
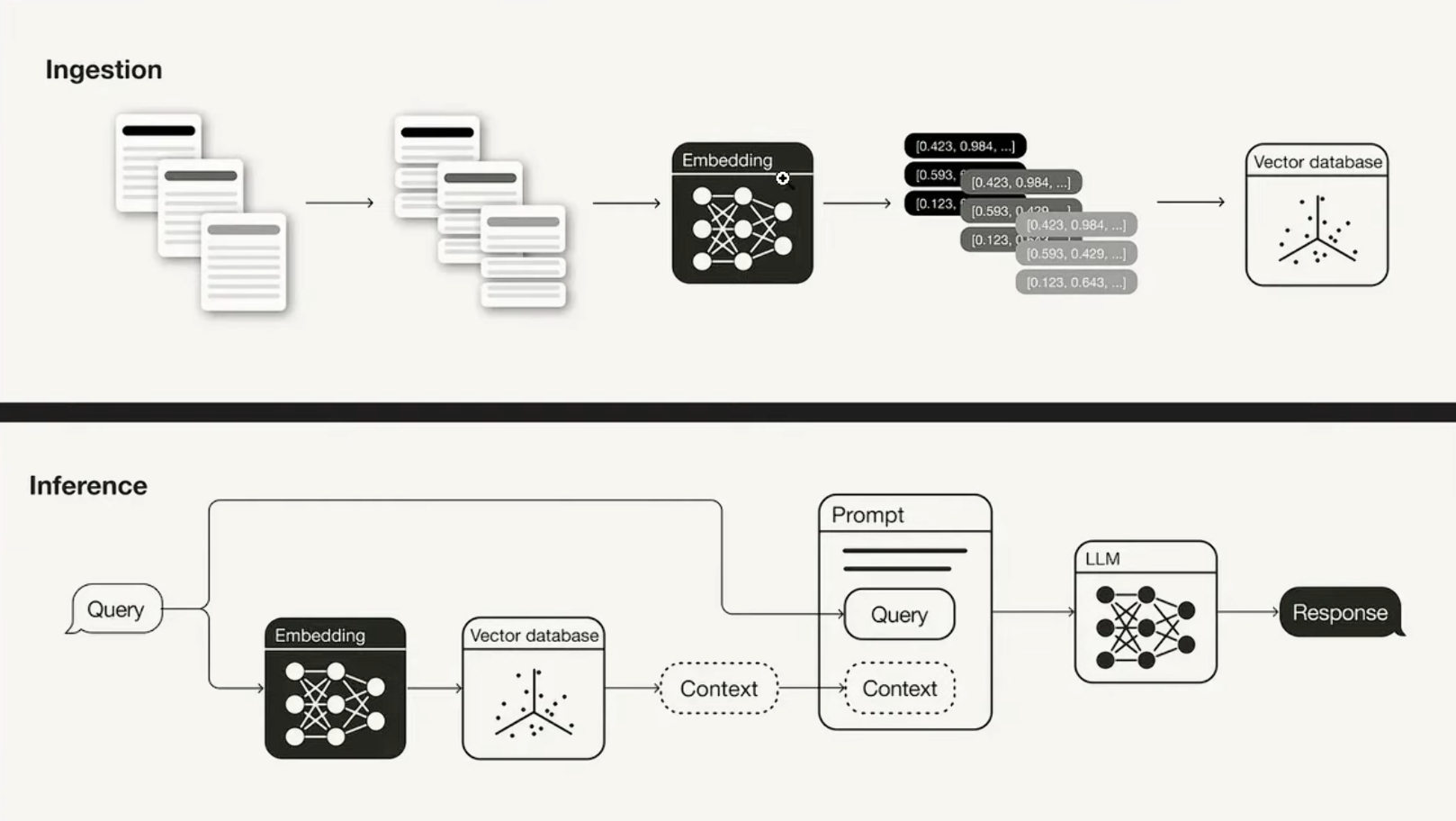
Dify RAG知识库
原理
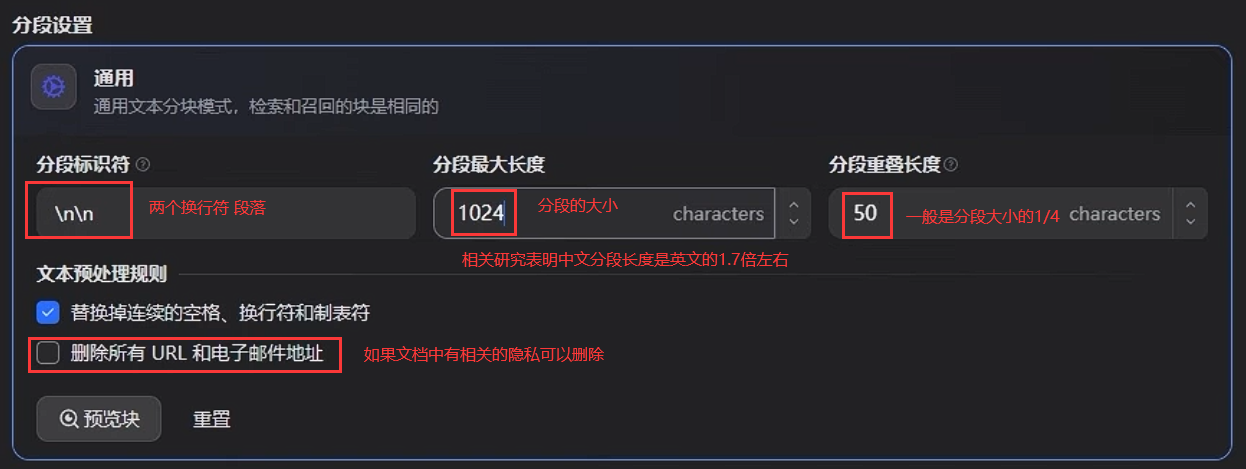
RAG 分段设置
1、通用分段
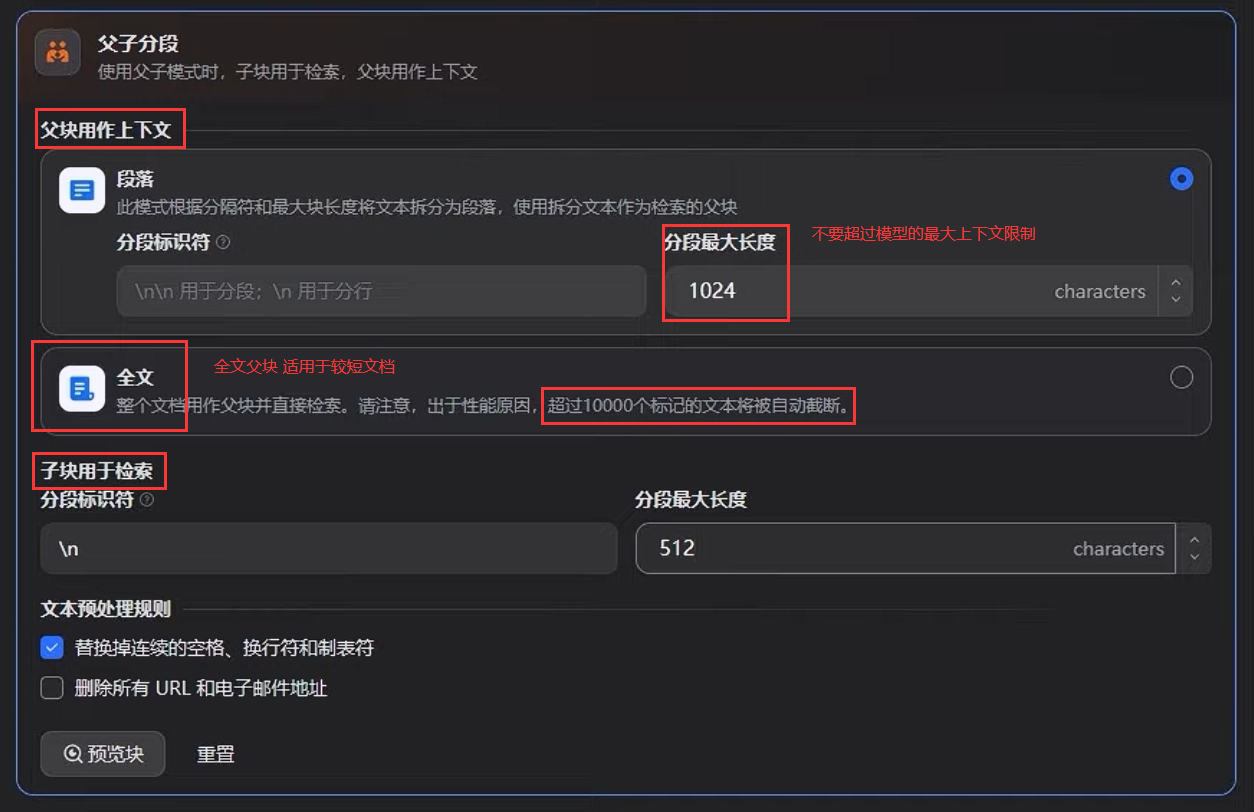
2、父子分段
RAG检索设置
向量检索
- 把用户问题转成向量,再和知识库分段向量比相似度,找“语义最接近”的内容。
- 优点:能理解“意思相近但措辞不同”的问题,跨语言能力也更强。
- 缺点:对精确术语、编号、特定关键词有时不如关键词检索稳定。
- 适用场景:FAQ、自然语言问答、多语言内容。
全文检索
- 基于倒排索引做关键词匹配,返回包含这些词的文本片段。
- 优点:对专有名词、报错码、产品型号、法规条款编号很有效,速度和成本通常更友好。
- 缺点:不太擅长理解同义表达和隐含语义。
- 适用场景:用户知道明确术语,或要查“原词出现的位置”
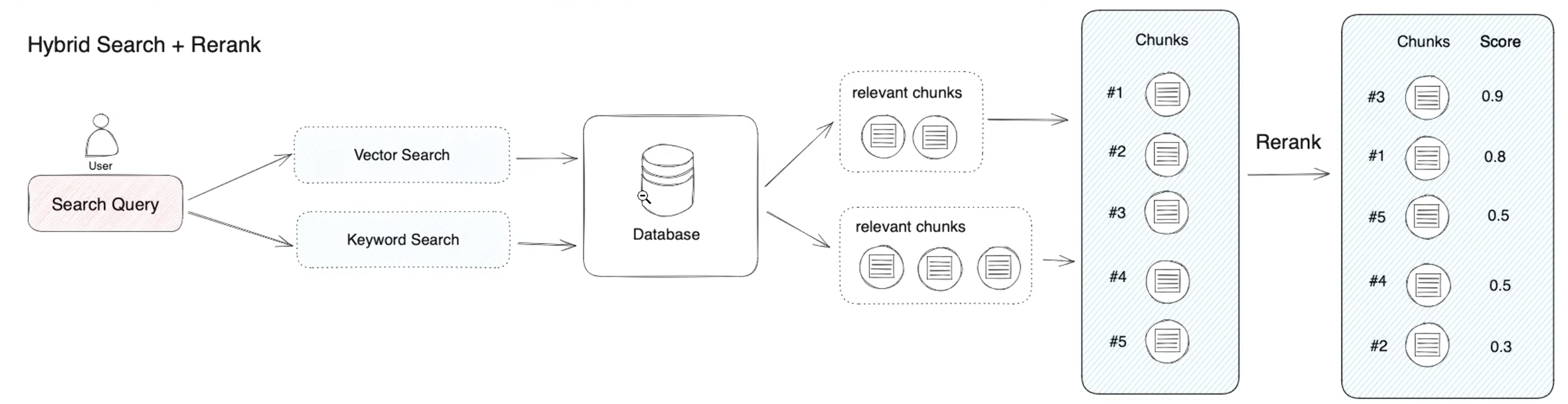
混合检索
- 同时执行向量检索和全文检索,再做重排序,从两类结果里选更好的答案片段。
- 优点:兼顾语义理解和关键词精确匹配,通常是最稳妥的通用方案。
- 缺点:配置更复杂,若启用 Rerank 还会额外消耗模型成本。
- 适用场景:大多数正式生产场景,尤其文档类型复杂时。
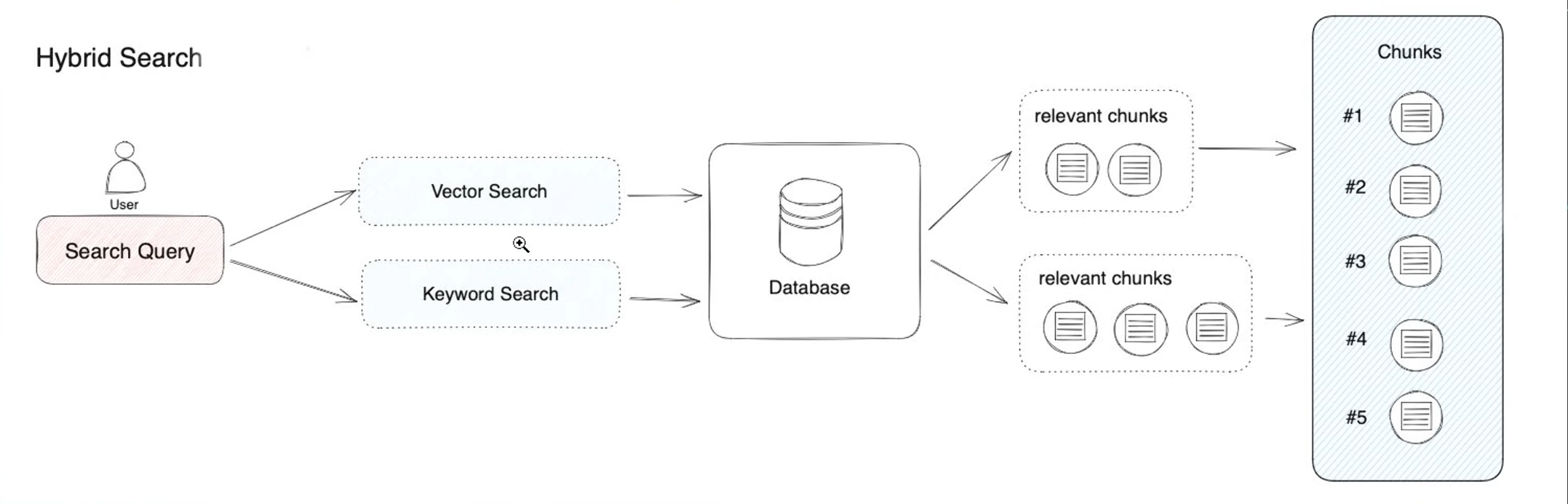
总结:
- 向量检索找“意思”。
- 全文检索找“关键词”。
- 混合检索两者都找,再挑更好的结果。
Rerank模型
版权声明:
作者:Gweek
链接:https://bbs.geek.nyc.mn/archives/254
来源:Gweek postHub
文章版权归作者所有,未经允许请勿转载。
THE END
二维码

共有 0 条评论